Decentralized Cloud Storage is changing the face of the internet

That one single development since the only remaining century, which likely has the most noteworthy effect on our lives today is the web.
It began as a decentralized environment back in the good ‘ol days. The open protocols like TCP/IP and SMTP helped construct various types of uses on the web like the World Wide Web, messaging administrations, and informing. In any case, the web, s we realize it today is completely unified, and organizations are putting vigorously in immense server cultivates that hold every one of our information and data.
A lot of ‘centralization’ is gradually slaughtering the online environment
Centralization has its own one of a kind advantages, which include:
- Higher rates
- Low dormancy
- Higher accessibility
- Fast throughput
Be that as it may, every one of these advantages come at the expense of serious downsides like information hacks and security breaks, restrictions, and absence of power over your information, to give some examples. On the off chance that you cautiously watch, the web is overwhelmed by a couple of innovation organizations, the ‘Huge Tech’. Indeed, the web is commanded by just a bunch of ten major organizations, as indicated by a blog entry distributed by Mashable. An excess of centralization additionally implies that the administrations can boycott your entrance to any application, leaving you with no different choices at all.
Hacks, restrictions, and blockage are boundless in the brought together framework
One ongoing model originated from Turkey where the administration restricted Wikipedia in 2017, asserting it was a ‘danger to their national security’. China has blocked access to mainstream internet based life, web crawler stages, and supplant them with applications that accompany heaps of government reconnaissance, content blockage, and control. So now the inquiry emerges, how might we make the web decentralized again with no restriction and progressively open control? All things considered, it is positively conceivable as an ever increasing number of progressions have been made into the ‘decentralized distributed storage’ space, which we will talk about additional right now.
What is Decentralization, and how can it apply to distributed storage?
Decentralization, as far as innovation, implies that the framework doesn’t depend on a focal position, it doesn’t have a solitary purpose of disappointment. In increasingly specialized terms, decentralization is a subset of circulated engineering where the dynamic is performed autonomously by all the taking an interest hubs, rather than depending on a solitary hub. Decentralization has been around for a long time, and it has more to do with administration, dynamic, and control.
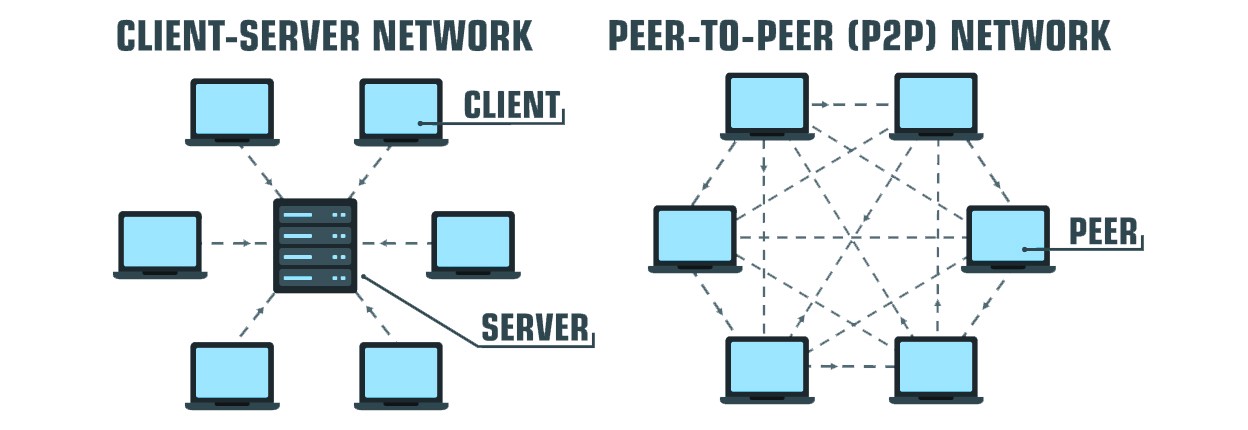
The soonest case of a decentralized framework is simply the web, where the sites were facilitated on singular PCs, trailed by Napster and BitTorrent, which established the framework for distributed (p2p) document sharing. BitTorrent protocol turned into the most well known and generally embraced is as yet utilized today in a wide range of utilizations.
At the point when we talk about distributed storage, ‘decentralized distributed storage’ implies that you can store your information, not on one single server or area, yet a wide range of hubs spread over different areas. These hubs are free of one another as far as complete authority over dynamic. It is very like BitTorrent protocol where the clients have documents on their nearby stockpiling and go about as ‘seeders’ (imparting lumps of records to different clients who need to recover them), however there are some basic contrasts.
Decentralized distributed storage is made conceivable by the new protocol for the disseminated web named IPFS (InterPlanetary File System). In the following part, we will plunge somewhat more profound into the IPFS protocol. We will likewise talk about how it separates from the BitTorrent protocol, which is additionally worked for dispersed distributed (p2p) document sharing over the web.
IPFS and how it fabricates the establishment for the decentralized distributed storage
IPFS (InterPlanetary File System) is a protocol created by Protocol Labs for the dispersed snare of things to come. It plans to challenge the customary HTTP protocol by building a progressively disseminated and decentralized system. Both HTTP and IPFS are hypermedia protocols worked for the web, to move any information among customer and server over the web. Be that as it may, there are inconspicuous contrasts between the two, truth be told, IPFS means to supplant HTTPS to turn into the default protocol of the web.
Rather than a solitary server, IPFS chips away at a colossal swarm of hubs that store various squares of information and clients getting to the system can recover this information from the closest hub.
The following is the short clarification of what befalls the documents on the IPFS organize:
- The record is isolated into pieces of information called squares. Each square is given a one of a kind hash.
- IPFS takes a shot at deduplication, which implies that all the repetitive documents are expelled from the system.
- Each hub partaking in the IPFS arrange stores the substance with its hash and some ordering data.
- At the point when a client needs to recover the document, he is advising the system to discover a rundown of hubs that have the substance behind a specific hash.
- With IPNS, a decentralized naming framework, each document can be effortlessly found by intelligible names.
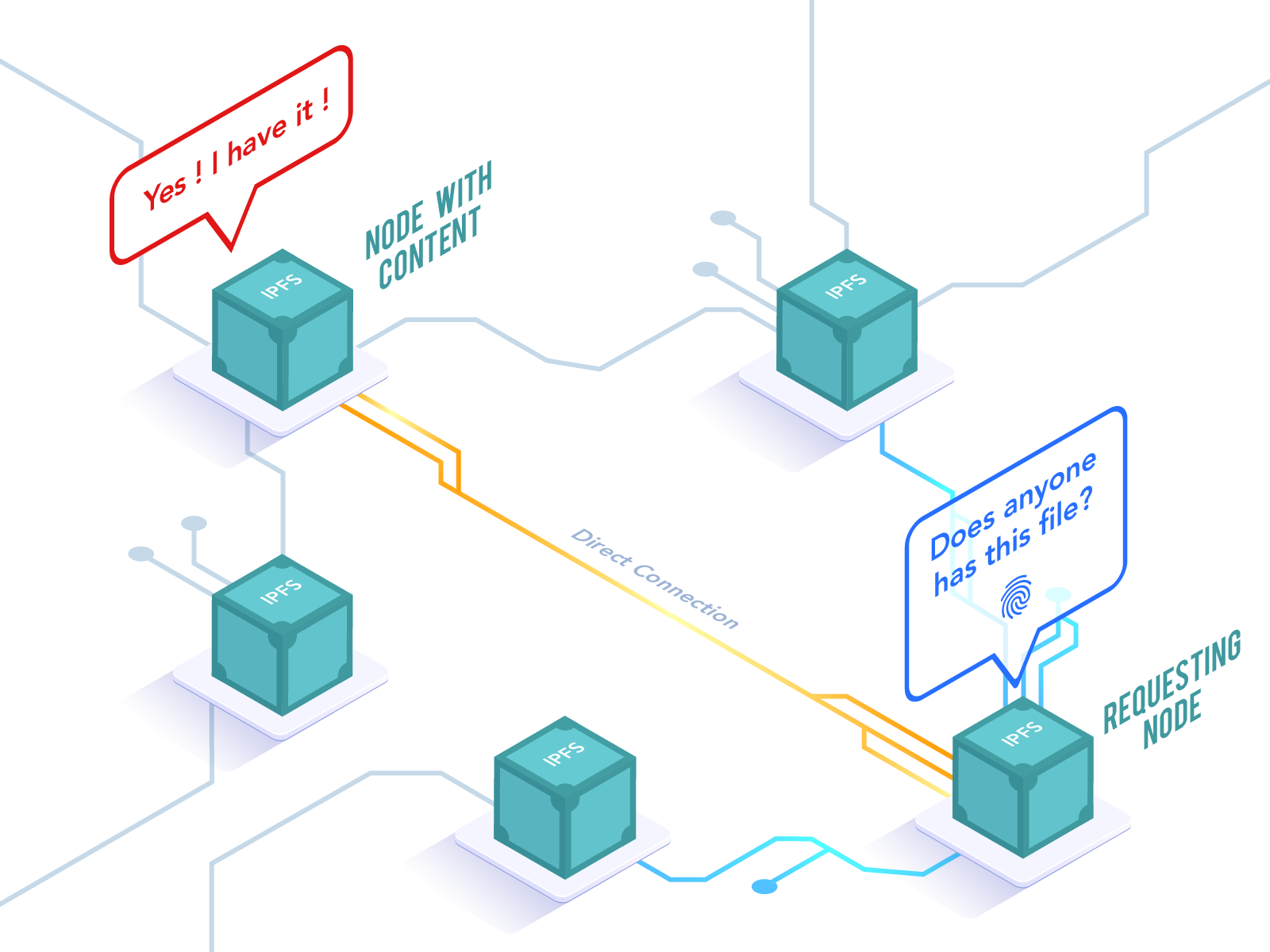
One other critical distinction among IPFS and HTTP is the means by which they address the substance over the web. HTTP essentially utilizes something many refer to as ‘area based tending to’ where you recover the substance by tending to its area, which is the IP address of the server facilitating that bit of substance.
Then again, IPFS utilizes something many refer to as ‘content-based tending to’ where you recover the substance by either its name or a special hash since the IPFS has deduplication all over the system, which implies that each hub is facilitating elite substance that makes ‘content-based tending to’ more proficient and dependable than the customary area based tending to.
How the IPFS separates itself from the BitTorrent ?
The IPFS sounds fundamentally the same as the BitTorrent protocol as them two are dispersed. Be that as it may, the two of them are essentially totally different from one another from multiple points of view. How about we examine a couple of key contrasts between the IPFS and BitTorrent protocol.
- IPFS is built for the web meaning to supplant HTTP while BitTorrent is just worked for distributed (p2p) record sharing. IPFS has deduplication the whole way across the system, which spares a huge amount of transfer speed and assets. Notwithstanding, BitTorrent doesn’t have any deduplication, which implies that there is an exceptionally substantial excess the whole way across the system.
- IPFS utilizes ‘content-based tending to’ to recover the records while BitTorrent utilizes Trackers to find the companions, which use ‘area based tending to’ simply like standard DNS and HTTP.
- All the information on IPFS is ‘permanent’, simply like Blockchain, and it has a forming framework worked in which monitors various variants of a similar document. BitTorrent protocol doesn’t have this unchanging nature and forming framework.
- IPFS has the ability of being a disconnected first system that can altogether help in quite a while or building up the world. BitTorrent doesn’t have any disconnected dressing component worked in.
- With the hashing, content-based tending to and unchanging nature, IPFS is ‘blockchain prepared’. Truth be told, numerous blockchain stages are utilizing IPFS for conveyed record stockpiling as of now. BitTorrent, then again, is most appropriate for distributed (p2p) record sharing over the protocolal web model.
Shouldn’t something be said about protection? Is decentralized distributed storage secure?
Blockchains are changeless without a doubt. Decentralized record stockpiling puts another danger on the table: protection, security, and trustworthiness of information. Luckily, it has been taken into solid contemplations, and diverse blockchain stages deal with it in their one of a kind ways.
Most of the applications that we will examine right now start to finish encryption and sharding. Prior to the dispersion of records into the decentralized world, it is separated into squares, and those squares are encoded and afterward disseminated among various hubs. For the record recovery, you have to have your private key to unscramble the documents.
Notwithstanding, this is only a more extensive point of view of how secure decentralize distributed storage is. With no focal area of your documents and with encryption incorporated with the framework, decentralized distributed storage may be more secure than the bring together arrangements accessible today.
With regards to IPFS, there is a problem — Why would the clients use their neighborhood stockpiling to store lumps of information for the IPFS organize? How are they boosted?